GPT는 왜 모르는 글자가 없을까? - BBPE (Byte-level Byte-Pair Encoding)
GPT를 활용한 챗봇을 개발하며 문득 이런 생각이 들었다.
- 정해진 vocabulary 안에서 나오지 않는 단어나 이모티콘은 어떻게 처리해 하나?
- 복잡한 테이블이나 코딩의 기호들은?
궁금증에 앞서 일단 토그나이저의 동작이 어떻게 이루어지는지 간략하게 다시 살펴보았다. (요즘 기억력이 점점 안좋아지는것 같다..)
Tokenizer method
word-based tokenizer
단어 기반 토큰화는 단어를 기반으로 토큰을 할당하게 된다.
예를들어 띄어쓰기를 기준으로 단어로 인식한다고 가정하면 나는 너를 사랑해 라는 문장은 나는, 너를, 사랑해 로 구분할 수 있다.
corpus에 따라서 vocabulary의 크기가 매우 커질 수 있다. 예를들어 사랑은 좋은것이야, 나는 너를 사랑해 두 문장이 있다면 사랑은, 사랑해 라는 같은 의미의 토큰이 두개가 생기고 서로 연관성 설명이 어려워진다.
만약 corpus에 없는 단어가 발생한다면 <unk>와 같은 임의의 토큰을 할당해야 한다.
character-based tokenizer
문자기반은 문자 하나씩 하나의 토큰으로 할당한다.
나는 너를 사랑해 라는 문장은 나, 는, 너, 를, 사, 랑, 해 로 변환된다.
영어의 경우에는 a, b, c,.. 처럼 의미 없는 단위로 떨어지지만 한국어와 같은 언어에서는 의미 단위가 있는 단어 (나) 와 의미가 분할된 단어 (사, 랑, 해) 가 생길 수 있다.
토큰이 너무 많아지기 때문에 연산량과 같은 부분에서도 비효율적이게 된다.
subword tokenizer
위 두가지 방식의 중간쯤(?) 되는 방식이다. 문자 수준 + 빈번하게 쓰이는 문자 조합을 이용해서 vocabulary를 생성한다.
나는 너를 사랑해, 나는 사람 입니다, 나와 너를 만나, 라는 corpus가 있다면 우선 문자 단위로 나 는 너 를 사 랑 해 람 입 니 다 와 만 와 단어 단위로 나는, 너를, 사랑, 사람 등이 추가될 수 있다.
특히 사랑해서, 사랑했기에, 사랑했어서, 사랑의, 사랑에 등과 같이 의미 단위에 따라서 반복되는 단어들은 사랑 + 해서, 했기에, 했어서, 의, 에 등으로 더 단어 빈도가 높은 사랑 이라는 단어와 이하 하위 단어의 합성 조합으로 만들어 질 수 있다.
토큰들이 각각 의미를 가지고 있고 조합에 의해서 단어가 만들어지기 때문에 같은 vocabulary 크기대비 더 다양한 문자를 표현 가능하다.
여기서 잠깐 얘기하자면 아무래도 OpenAI에서 개발하는 GPT는 한국어 토크나이저에 힘을 덜 쓸수 밖에 없고 이로 인해서 같은 문장이라도 더 많은 토큰을 사용할 수 밖에 없다. 이는 컴퓨팅 비용의 증가와 서비스 사용 비용의 증가로 이어지기 때문에 한국어가 LLM에서 불리해질 수 밖에 없다. 이를 타파하기 위해서 네이버의 클로바 X에서는 토크나이저에 신경을 많이 썻다는데 구조가 궁금하다.🤔
BPE(Byte-Pair Encoding)과 BBPE (Byte-level BPE)
Subword Tokenizer에는 BPE, WordPice, Unigram 등 다양한 방법들이 있지만 GPT2 이후로 GPT 에서는 BPE 방식, 그중에서도 BBPE를 사용한다고 한다.
간단하게 얘기하면 위에서 들었던 예시에서 나 는 너 를 사 랑 해 람 입 니 다 와 만 의 문자 단위로 구분한다. 다음으로 병합 규칙을 이용해서 빈도 수에 따라, 조합인 나는, 너를을 추가하게 된다. 이와 같이 조합 단어를 추가해 가며 목표 크기까지 vocabulary를 만들게 된다.
여기까지 왔는데 의문이 들었다. 어떻게 GPT2 논문에서 BBPE를 사용해서 효과적으로 토크나이저를 만든걸까?
BBPE는 BPE와 같지만 byte-level에서 BPE를 수행한다고 한다. 이 의미가 무었일까?
위의 예제로 다시 돌아가서 나는 너를 사랑해, 나는 사람 입니다, 나와 너를 만나 라는 corpus가 있다면 단순 BPE는 문자에 따라서 나 는 너 를 사 랑 해 람 입 니 다 와 만 를 기본 토큰으로 토큰을 만들어 간다. 하지만 BBPE는 이 단어를 byte 단위로 더 쪼갠다. 만약 한글이 유니코드로 표현되었고 UTF-8로 인코딩 된다고 하면, 나 -> U+B098(유니코드) -> \xeb, \x82, \x98 (UTF-8 인코딩) 으로 변환될 수 있다.
1
2
3
words = '나'
words_byte = bytes(words, 'utf-8')
print(words_byte)
1
b'\xeb\x82\x98'
BBPE는 바로 이 문자보다 더 작은 단위인 바이트 \xeb, \x82, \x98, … 를 최고 작은 단위의 토큰으로 할당하는 것이다.
여기서 다시한번 배운 사실이 있었는데 유니코드 자체는 글자와 코드를 연결하는 규칙(위의 예시 처럼
나->U+B098)이고, UTF-8과 같은 인코딩의 역할은 유니코드인U+B098값을\xeb,\x82,\x98와 같이 byte로 인코딩 하는 방법이라는 점이다. 반성해야겠다.😥
BBPE가 왜 더 좋을까?
단순히 보면 BBPE가 오히려 기본 토큰 수가 늘어나고 복잡해 보인다. 그러나 여기에는 숨은 이유가 있었다.
나는 단순히 단어만 보고 BPE가 더 이득이 아닌가? 의문을 품었지만 유니코드는 최대 1,114,112의 코드 포인트를 가질 수 있다고하는 글을 보고 그 이유를 알 수 있었다. (저 작은 문자 단위의 토큰이 최대 1,114,112개가 될 수 있다는 소리..!!)
반면 byte level 까지로 나누면 한 문자를 표현하기 위한 토큰은 늘어난다고 해도 (subword에 의해서 꼭 늘어나지만 않을 수도 있다.) 최소 단위 토큰은 1byte, 즉 256개의 토큰 조합으로 subword를 머지해나갈 수 있다는 의미이다.
추가적으로 vocabulary에 없는 단어가 발생하는 경우의 대처도 더 유연하게 할 수 있다. BPE의 경우에는 최대 코드 수 인 1,114,112 개의 토큰을 모두 사용할 수 없고 더 작은 문자 단위로 구성하게 될텐데 매우 희귀한 단어의 경우에는 토큰으로 사용되지 못한 문자를 만날 수 있다. (특히 이모지, 특수기호 와 같은 문자), 하지만 BBPE는 모든 글자를 byte 단위로 쪼개기 때문에 새로운 단어가 입력으로 들어오더라도 <unk> 토큰이 아닌 바이트 단위 토큰의 조합으로 할당할 수 있다.
아래는 실제 GPT의 토크나이저로 테스트한 결과이다.
1
2
3
4
from tiktoken._educational import *
enc = SimpleBytePairEncoding.from_tiktoken("cl100k_base")
enc.encode("한글 문자 꿍 꿩 퇑")
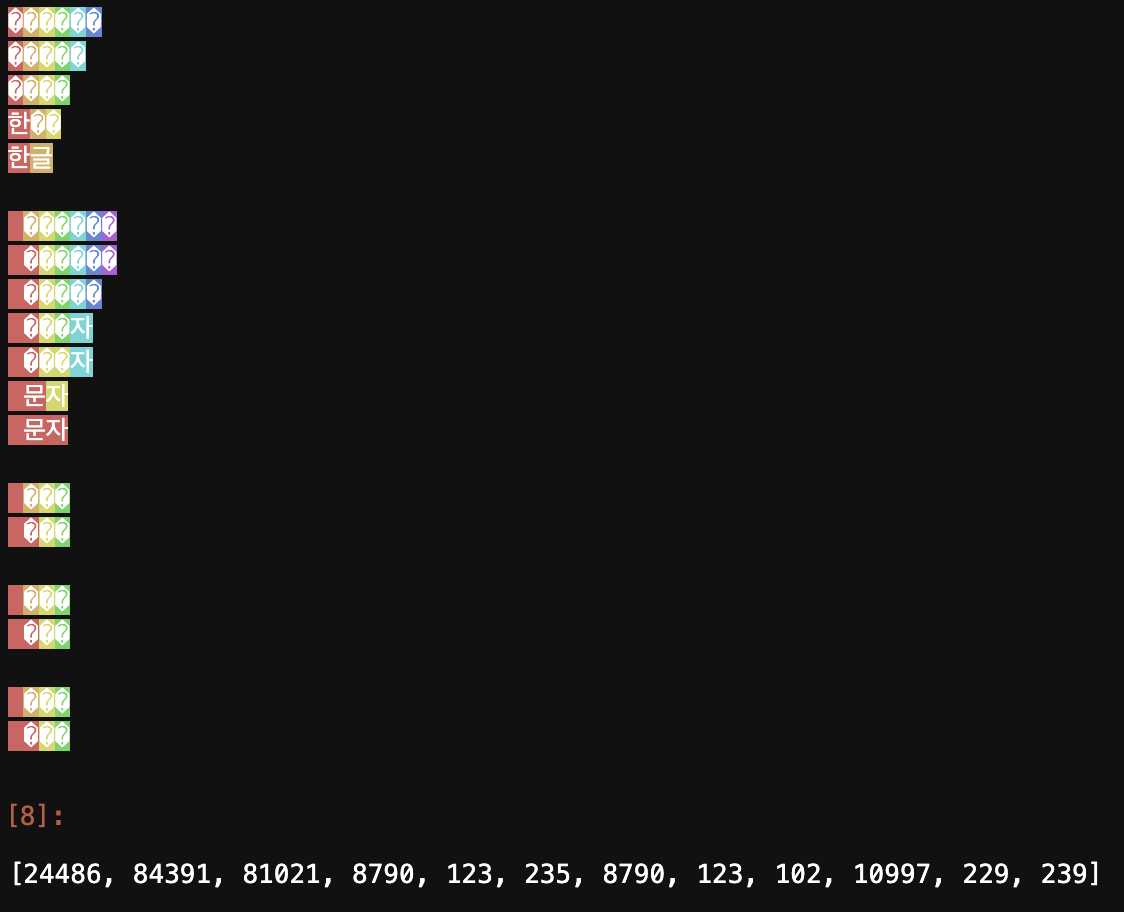
결과를 살펴보면 한글은 한, 글이 각각 하나의 토큰으로, 문자는 하나의 토큰으로, 꿍, 꿩, 퇑의 희소한 문자는 각각 byte로 분할되어 표기는 ?로 되었지만 토큰아이디 기준 각각 [8790, 123, 235], [8790, 123, 102], [10997, 229, 239] 토큰으로 할당된 것을 볼 수 있다.
이 정도로 의문이 많이 풀린것 같다. 하지만 이리저리 자료를 찾아보며 무지함을 다시 느꼈고.. 역시나 공부를 더 해야겠다는 생각이 가득 느껴진다 💪