Deep Knowledge Tracing
Knowledge Tracing 이란
학생들의 시간에 따른 지식 정보(어떤 유형을 잘 배웠는지, 못하는지)를 모델링하는 task. 이렇게 모델링된 함수를 사용하여 학생들이 다음 문제를 풀었을때의 맞고 틀리고를 예측할 수 있다.
Deep Knowledge Tracing(DKT) 이전의 Knowledge Tracing은 제한된 형태의 Markov chain을 기반으로한 모델이 대부분이였다.
Deep Knowledge Tracing
유연한 RNN을 적용해서 시간에 따른 knowledge tracing이 가능함을 보임.
- RNN 모델을 적용
- 기존의 Knowledge Tracing 모델들 보다 AUC에서 25% 정도의 향상이 있음
- 학생들의 문제나 관계에 따른 전문적인 annotation이 필요하지 않음
- 문제들의 영향이나 문제 커리큘럼을 작성하는데 도움을 줄 수 있음을 제시
Knowledge Tracing 문제 정의
특정 learning task에 대한 학생들의 interaction(문제를 풀고 맞거나 틀린 상황)이 \(\mathbf{x}_0\ldots\mathbf{x}_t\) 로 주어진다고 할때 \({ \mathbf{x}_{t+1} }\)에서의 양상을 예측하는것.
$q_t$를 문제 유형 태그라고 하고 해당 문제에 대해서 맞았는지 여부를 \(a_t\)라고 하면 interaction은 튜플 \(\mathbf{x}_t = \{ q_t, a_t \}\)로 표기될 수 있다.
예측할때는 모델이 \(q_t\)를 입력으로 받아서 정답을 맞췄는지 \(a_t\)를 출력으로 내보낸다.
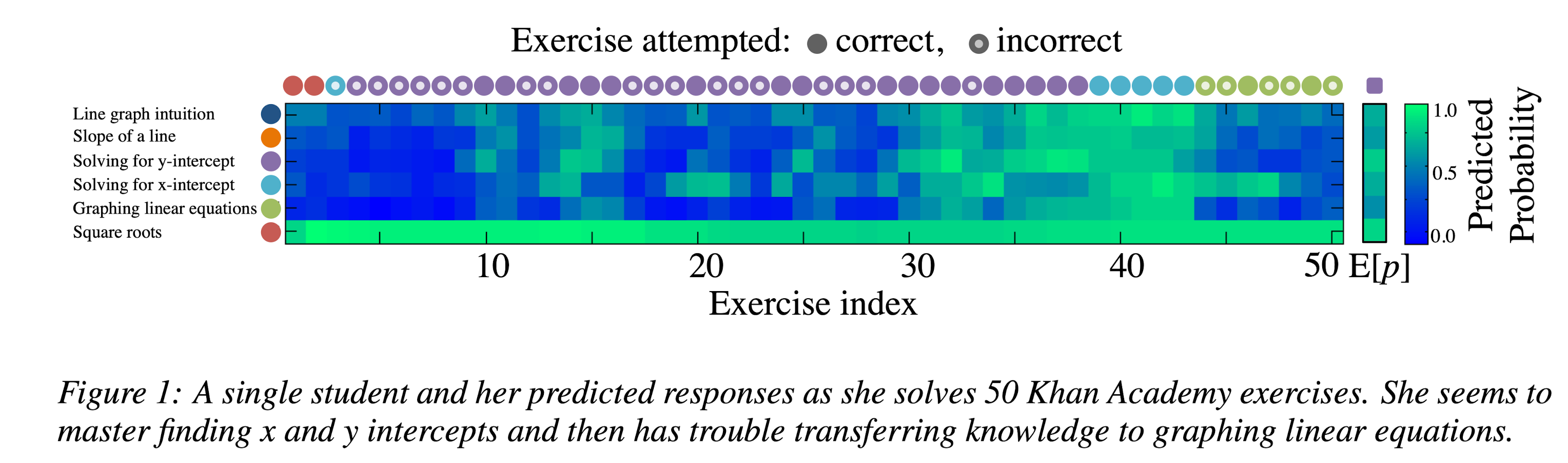 모델이 완성되면 모든 tag에 대한 예측을 해서 학생의 정답률을 문제 유형별로 출력해볼 수 있다.
모델이 완성되면 모든 tag에 대한 예측을 해서 학생의 정답률을 문제 유형별로 출력해볼 수 있다.
Model
기존의 Knowledge Tracing은 전문가가 학습 내용을 정리하고 분류하는 전문적인 작업이 필요하였으나 RNN을 도입하여 스스로 hidden layer를 통해서 분류 통찰을 배우도록 구성하였음.
학습에 사용된 RNN은 기본 구조와 같은 형태를 띄고 있음.
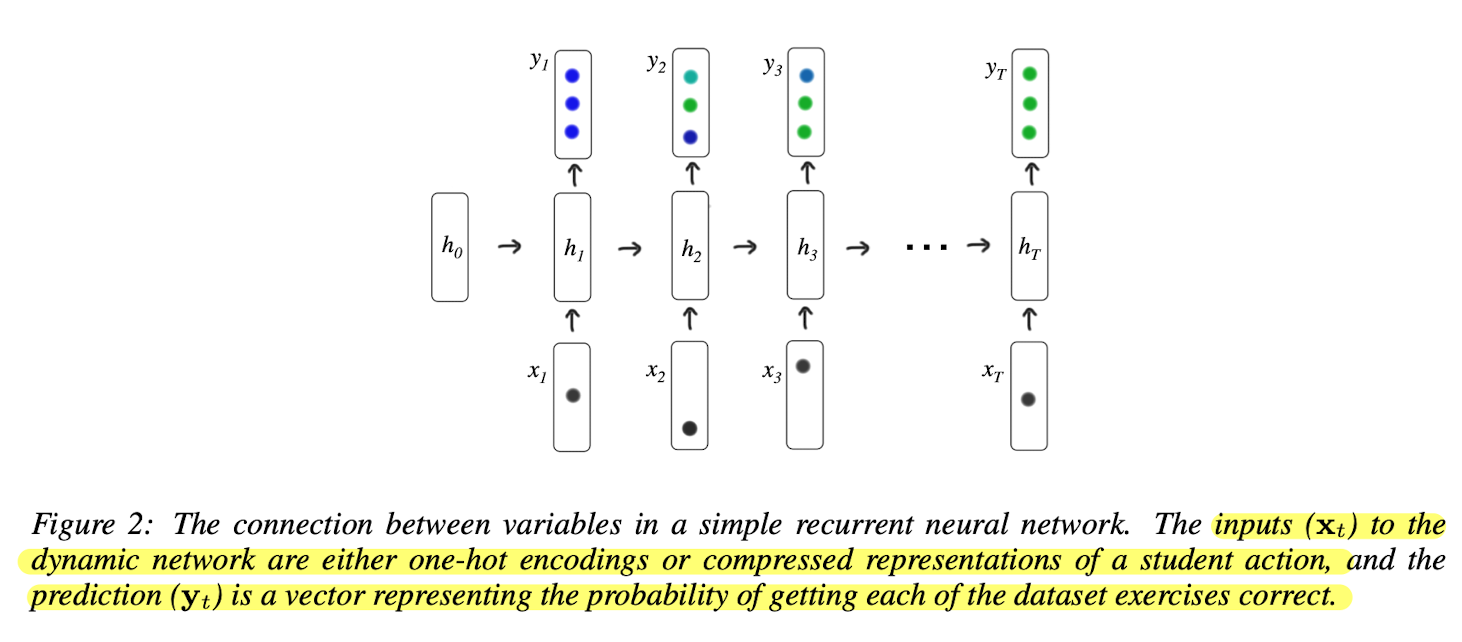
Dataset processing
데이터 tag의 수가 적은 경우
공식 리포(Lua)를 살펴보면 해당코드에서 interaction $\mathbf{x}_t$를 구하는 코드를 확인할 수 있다. index를 구하는 코드를 살펴보면 아래와 같은것을 볼 수 있다. 해당 인덱스를 1로 두어서 one-hot vector를 구성한다.
1
local xIndex = correct * self.n_questions + id
풀어서 설명하면 one-hot vector는 다음과 같이 만들어진다.
1
2
[0태그의 문제를 틀린경우, 1태그의 문제를 틀린 경우, 2태그의 문제를 틀린 경우, ...
0태그의 문제를 맞춘 경우, 1태그의 문제를 맞춘 경우, 2태그의 문제를 맞춘 경우 ... ]
[계산 예시]
$\mathbf{x}_t = { q_t, a_t }$ 를 시간에 따라서 풀어서 입력, 아래와 같은 조건을 가정할때
- $q_t$(M개의 문제 유형 태그) $\in$ {0, 1, 2, 3, 4}
- $a_t$(정답 여부) \(\in\) {0, 1}
- 위의 조건에 따라서 만들어지는 one-hot vector의 크기는 $x_t \in {0, 1}^{2M}$, 2M = 10길이의 vector.
아래와 같은 예시 데이터가 있다고 가정한다.
$\mathbf{x}_{t=0 \sim 7}$ = [{0, 0}, {2, 0}, {1, 1}, {4, 0}, {3, 1}, {3, 1}, {2, 1}, {0, 1}]
이를 표로 나타내면,
| 시간 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| $q_t$ | 0 | 2 | 1 | 4 | 3 | 3 | 2 | 0 |
| $a_t$ | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 |
위의 인덱스 계산법에 따라서 one-hot vector를 구성하면 다음과 같다.
1
2
3
4
5
6
7
8
9
10
[
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
]
데이터셋의 문제 카테고리가 100개라면 $x_t$는 200의 크기를 가진 벡터가 된다.
데이터 tag의 수가 많은 경우
앞서 태그의 수가 작은 경우 one-hot vector의 형태로 넣었던것을 임베딩된 배열 형태로 넣게 된다. NLP에서 토큰이 많을때의 경우를 생각해보면 될것 같다.
Optimization
관찰된 시간에 따른 sequence의 negative log likelihood를 objective loss로 사용한다. $\delta{(q_{t+1})}$을 $t+1$ 시점에서의 one-hot encoding 이라고 하고 $\ell$ 을 binary cross entropy 라고 할때 loss는 다음과 같이 주어진다.
\[L = \sum_{t} \ell(\mathbf{y}^T \delta{(q_{t+1})}, a_{t+1} )\]이때 binary cross entropy를 사용하는 이유는 DKT 모델의 output과 관계가 있다.
아래와 같이 문제는 4개 카테고리, 실제 데이터는 3문제를 푼 사람이 있다고 하자.
이때 입력과 출력이 다음과 같이 주어진다.
여기서 input[t] 입력일때, input[t+1]의 category에 해당하는 output만 이용하여 [t]시점의 correctness를 학습한다.
(즉, 주어지는 다음 입력이 특정 category에 대한 correctness 이므로 해당 category의 정답 가능성만 BCE를 통해서 계산한다.)
Applications
학습된 모델은 학습 커리큘럼 디자인 (Expectimax Search algorithm을 활용) 이나 데이터의 내적 컨셉을 이해하는데 활용될 수 있다.
후자의 경우 exercise \(i\) 와 \(j\) 사이의 영향력$J_{ij}$를 다음과 같이 계산하였다.
\[J_{ij} = { {y(j \mid i)}\over{\sum_ky(j \mid k)} }\]이때 \(y(j \mid i)\)는 exercise $i$에 대해서 정답을 맞췄을때 exercise $j$에 대한 RNN의 정답 확률을 나타낸다.
Appendix
Assistment Dataset Preprocessing
저자의 Lua 구현체를 보면 Assistments 2009-2010 “skill builder” 데이터셋을 사용하는 것을 볼 수 있다.
다운로드는 논문의 링크에서 변경되어서 여기서 확인 가능하다. 데이터의 구조는 저자 리포와 현재 해당 링크의 구조가 조금 달라보인다.
저자 리포에 있는 데이터의 전처리 방법을 확인해보았다.
파일 구조는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
4
51,51,51,51,
0,1,1,1,
9
82,82,82,82,82,82,82,82,82,
0,0,1,1,1,1,0,0,1,
20
0,0,0,0,0,9,9,9,11,11,12,12,12,12,12,14,14,14,14,14,
1,0,1,1,0,1,1,1,0,0,1,1,1,1,1,1,1,1,1,1,
1
82,
1,
1
82,
0,
49
37,37,45,45,45,45,55,55,55,55,55,55,79,79,79,79,79,79,79,80,80,80,80,80,82,82,82,82,82,82,82,123,123,123,123,123,123,123,123,123,123,123,123,123,123,123,123,123,123,
0,1,1,1,1,0,1,0,1,1,0,1,0,1,0,1,1,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,1,1,1,1,1,0,0,0,0,1,0,0,0,0,0,1,0,
3줄씩 나눠서 하나의 블럭으로 보고 각 줄을 다음처럼 해석할 수 있다.
1
2
3
local nStepsStr = io.read() -- 총 문제 푼 횟수.
local questionIdStr = io.read() -- 문제 ID.
local correctStr = io.read() -- 맞춤 여부.
데이터의
nStepsStr가 단 몇개부터 몇백개까지 다양하기 때문에 코드를 보면max_steps를 제한할 수 있도록 되어있지만 default가 nil로 설정되어있다.
다음으로 student라는 table을 만들어서 여기에 각 값들을 나누어서 넣어주고 있다.
questionId, correct는 0으로 채워진 torch array를 만들어주고 시작하기 때문에 데이터크기가 작은 경우는 0으로 padding 된 결과를 얻을 수 있다.
1
2
local student = {questionId = , correct = , n_answers = }
-- 여기서 questionId, correct 키들에 대한 값은 torch array로 만들고 길이는 n_answers 값으로 같다.
다음으로 위의 과정을 데이터 만큼 반복한다. 이때 값이 없거나 1개만 있는 경우는 제외하게 된다.
1
2
3
4
5
6
7
8
9
10
11
12
local trainData = {}
while(true) do
if(student == nil) then
-- (nStepsStr == nil or questionIdStr == nil or correctStr == nil) 조건이면 데이터를 추가하지 않음
break
end
if(student['n_answers'] >= 2) then
-- 답변이 2개 이상일때만 추가.
table.insert(trainData, student)
end
end
마지막으로 trainData table이 semiSortedMiniBatches function으로 들어가게 된다.
이 데이터는 앞서 설명한것처럼 다음의 크기를 가지게 된다.
1
2
3
4
5
6
7
8
9
local inputX = torch.zeros(n_students, 2 * self.n_questions)
-- the last student activity
local inputY = torch.zeros(n_students, self.n_questions)
-- the next question answered
local truth = torch.zeros(n_students)
-- whether the next question is correct
이 외에 코드를 보다보면 inputM 변수가 나오는데 RNN의 hidden layer 처음 입력으로 볼 수 있다. (0으로 초기화 시키는것을 볼 수 있다.)
Evaluation
검증은 ROC(Receiver Operating Characteristic curve)의 AUC 값을 이용한다.
앞서 데이터셋을 전처리 했을떄 아래에서 x가 실제 값이라고 한다면 0은 padding된 값을 의미한다.
1
2
batch = [[x11, x12, 0, 0, 0], [x21, x22, x23, x24, 0], [x31, x32, x33, x34, x35]]
n_answers = [2, 4, 5]
여기서 step을 하나씩 이동하면서 모든 prediction과 GT 값을 기록한다. mask 값을 이용해서 해당 step의 값이 진짜인지 padding인지 구분하고 있다. 위의 예제의 경우는 k(step)에 따라서 mask가 아래처럼 주어진다.
1
2
3
4
5
k = 1 : [1, 1, 1]
k = 2 : [0, 1, 1]
k = 3 : [0, 1, 1]
.
.
앞서 데이터를 처리할때 스텝의 길이가 2 이상만 데이터로 사용했기때문에 2번째 스텝부터 처리한듯 하다.
필터링된 데이터들을 모으면 아래처럼 된다.
1
2
local pred = { {x11, x21, x31},{x12, x22, x32},{x23, x33},{x24, x34},{x35} }
local gt = { {y11, y21, y31},{y12, y22, y32},{y23, y33},{y24, y34},{y35} }
마지막으로 모든 데이터에 대해서 순차적으로 FPR, TPR을 구하고 AUC를 구한다.