클라우드 환경에서 pytorch DDP 사용하기
모델을 빠르게 학습하고 피드백하려면 어떻게 해야할까? 더 좋은 GPU를 사용할 수도 있고 더 많은 GPU를 하나의 시스템에 설치할 수도 있다. 하지만 그 성능과 물량은 물리적으로 제한이 있다.
영상처리 모델을 학습해야하는데 모델의 크기와 데이터 하나의 크기는 크지 않지만 (LLM과 비교해서) 데이터의 개수가 6백만장에 가까워서 빠른 학습 및 검증을 시도하기 어려운 상황이였다. 이를 위해 클라우드 환경에서 DDP(Distributed data parallel)를 구성했고 mlflow와 skypilot을 사용하면서 필요했던 부분들을 기록해두려고 한다.
조건
- AWS g4dn series multiple node
- pytorch(1.12.0)
- mlflow (2.8.0)
- skypilot (0.5.0)
DDP
DDP 자체는 데이터를 분산하여 모델을 학습시켜서 학습속도를 증가시키는것이다. 하나의 시스템안에 GPU가 여러대 설치되어있다면 데이터를 나눠서 학습하고, 만약 여러 시스템에 각각 GPU가 설치되어있는 구조라면 각 컴퓨팅 리소스를 네트워크로 연결시켜서 학습하게 된다.
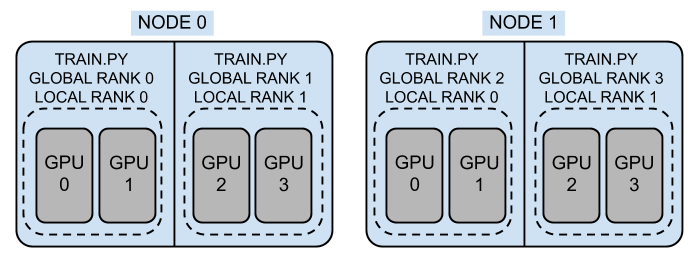 Fig.1. pytorch 에서 제공한 그림. 각 워커들을 노드라고 부르고 프로세스단위로 rank라고 부른다.
Fig.1. pytorch 에서 제공한 그림. 각 워커들을 노드라고 부르고 프로세스단위로 rank라고 부른다.
Federate Learning과 비슷한 전략이라고 볼 수 있는데 DDP는 중앙 집중적으로 학습하고 컴퓨팅 리소스의 관리권한이 모두 있기에 데이터를 균일하게 분포하고 보안문제에 비교적 자유롭다. Federate Learning은 edge 에서 데이터를 가지고 있고 학습을 하기 때문에 데이터의 검증이나 보안문제가 발생할 수 있고 공격에 취약할 수도 있다.
pytorch의 DDP는 다중 프로세스 병렬화를 통해서 GIL 문제 없이 병렬 학습을 가능하게 해준다. 학습 데이터는 DistributedDataSampler를 통해서 rank 수에 맞춰서 샘플링 되며 각 rank의 모델은 각 rank의 optimizer를 이용해서 학습 된다. Ring-AllReduce 알고리즘에 의해서 gradient를 동기화하게 된다. DDP에 관한 정보는 해당 논문에서 내용을 확인할 수 있다.
나의 경우에는 aws:g4dn 시리즈를 이용해서 학습해야했는데 서울 리전에서는 리소스가 그리 넉넉하지 않다는 답변을 받았고 특히 멀티 GPU를 가진 인스턴스는 리소스가 더 부족했다. 그래서 1rank에 1gpu가 할당되고 4개의 노드를 이용해서 학습을 진행했다.
(1)node-(1)rank
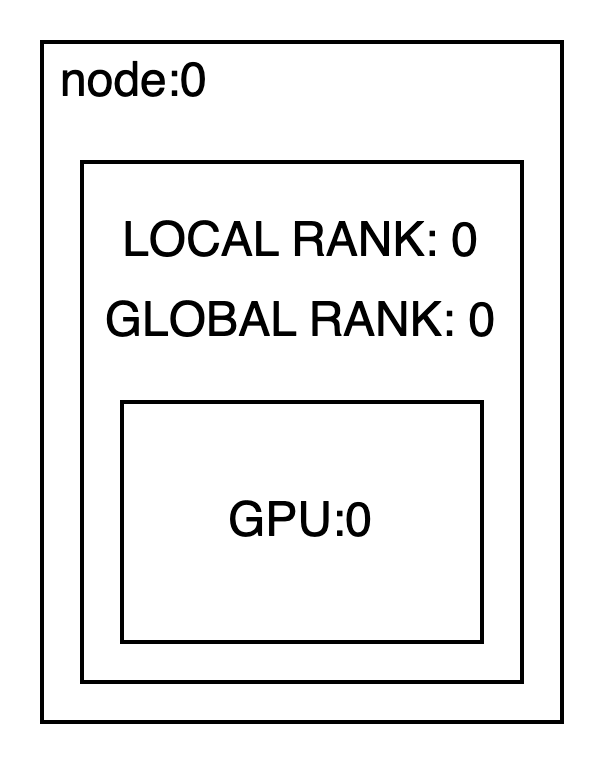
보안상 학습 코드를 공개할 수 없어서 torch example을 이용한다. 1node-1rank의 경우 gpu가 하나 달린 한대의 서버에서 1개의 학습 프로세스를 돌린다고 생각하면 좋다. 일반적으로 학습 구조는 다음과 같다. 프로세스도 하나이고 gpu도 하나이기 때문에 pytorch 기본 코드만으로 간단히 작성해도 잘 돌아간다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class MyDataset(Dataset):
...
class MyModel(nn.Module):
...
def train(epochs):
my_dataset = MyDataset()
my_model = MyModel().to(device)
my_loss = MyLoss()
optimizer = torch.optim.SGD(my_model.parameters(), ...)
my_dataloader = Dataloader(my_dataset, ...)
for epoch in range(epochs):
for data, target in my_dataloder:
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = my_model(data)
loss = my_loss(output, target)
loss.backward()
optimizer.step()
if __name__ == '__main__':
device = torch.device('cuda')
train(10)
(1)node-(N)rank
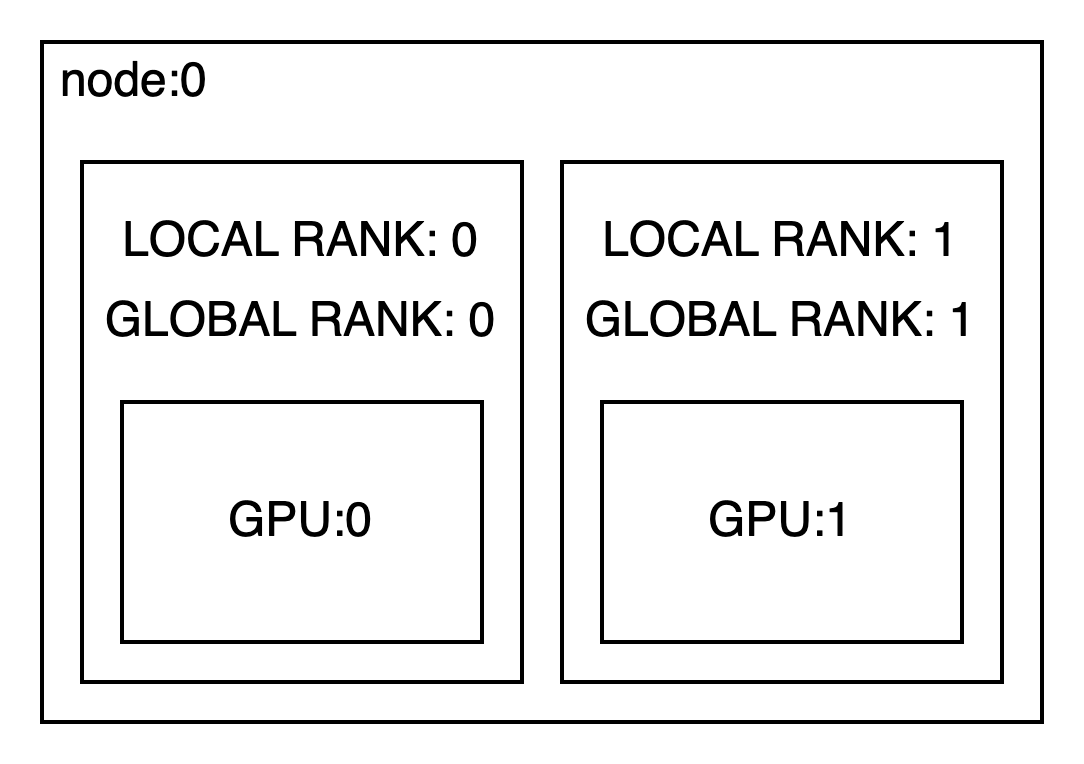
1개의 노드에 여러 랭크를 구성하는 방법으로 하나의 시스템에 여러 GPU가 물려있는 시스템이 대상이다. 각 GPU를 하나씩 물고있는 프로세스끼리 통신을 하며 학습을 진행하게 된다. 아래의 코드를 살펴보자. DDP의 경우 각 rank는 서로 다른 프로세스에 할당되어야 한다. 스크립트를 world_size에 맞춰 여러개 실행하는 방법이 있지만(아래에서 torchrun이라는 스크립트를 사용할 수 있다.) multiprocessing.spawn을 통해서 멀티프로세싱으로 train을 병렬 실행하는 형태로 구성 되어있다. 첫번째로 DDP를 위해서 통신 환경을 설정해야한다. 여기서는 NCCL(NVIDIA Collective Communications Library)을 backend로 통신하도록 하고 있으며 모든 프로세스에는 master 프로세스에 연결하기 위한 IP와 PORT 정보를 환경변수로 설정해야한다. Dataset을 각 rank로 적절하게 분배할 수 있도록 Dataloader에 sampler를 세팅하고 ( If specified, shuffle must not be specified.) 모델은 DistributedDataParallel로 감싼다. 또한 epoch마다 dataloader.sampler.set_epoch를 설정해서 각 peoch마다 shuffling이 잘 되도록 할 수 있다.
이경우에
nn.DataParallel(model)을 사용하기도 하지만 DataParallel은 하나의 프로세스에서 각 GPU의 데이터를 main gpu로 모아서 계산하기 때문에 메모리 사용량의 불균형이 생기고 낭비되는 GPU 메모리가 발생하게 된다. 또한 하나의 시스템에 장착 가능한 GPU의 개수는 한정되어있기 때문에 한계가 명확하다는 점도 있다. 다만 쉽게 구현이 가능해 빠르게 학습가능하거나 여유가 있는 환경에서는 선택이 될 수 있을것 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
class MyDataset(Dataset):
...
class MyModel(nn.Module):
...
def train(rank, world_size, epochs):
# 환경 변수를 통해서 master 노드의 주소를 작성해야한다.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12345"
init_process_group(backend="nccl", rank=rank, world_size=world_size)
# 동일한 노드 안에 GPU가 여러개 있기 때문에 rank에 맞춰서 GPU 할당.
torch.cuda.set_device(rank)
my_dataset = MyDataset()
# 모델은 DistributedDataParallel 감싼다.
my_model = DistributedDataParallel(MyModel().to(device), device_ids=[rank])
my_loss = MyLoss()
optimizer = torch.optim.SGD(my_model.parameters(), ...)
# dataset을 각 rank에 분배해야하기 때문에 DistributedSampler를 설정해준다.
my_dataloader = Dataloader(
my_dataset,
sampler = DistributedSampler(my_dataset),
...,
)
for epoch in range(epochs):
# epoch에 따라서 shuffle order가 변경될 수 있도록 설정.
my_dataloder.sampler.set_epoch(epoch)
for data, target in my_dataloder:
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = my_model(data)
loss = my_loss(output, target)
loss.backward()
optimizer.step()
if rank == 0:
# Ring-AllReduce에 의해 동일한 gradient를 가져서,
print("rank0인 master에서만 모델 저장.")
destroy_process_group()
if __name__ == '__main__':
# 동일 노드 안으로 world_size가 GPU개수와 같다.
world_size = torch.cuda.device_count()
# 두개의 프로세스를 동시 실행. 각 프로세스는 rank (0~ world_size) 할당.
torch.multiprocessing.spawn(
train,
args = (world_size, 10),
mprocs = world_size,
)
(N)node-(N)rank
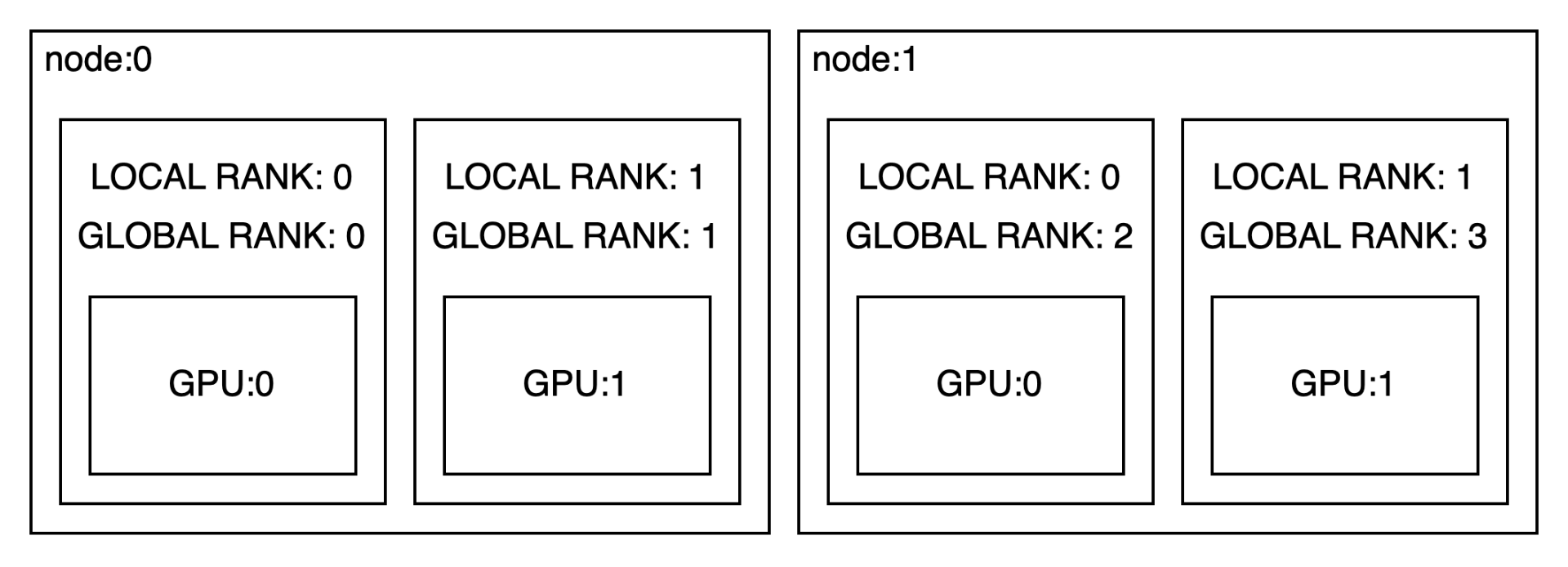
1node-Nrank까지만 해도 하나의 노드이기 때문에 모든 프로세스를 하나의 스크립트에서 멀티프로세싱으로 동작하는 방식으로 구성하였다. 하지만 노드가 N개로 확장되는 경우 모든 프로세스를 동시에 돌리기 어렵기 때문에 torchrun을 이용하게 된다. torchrun을 이용하면 여러 환경변수가 자동으로 생성되기 때문에 이를 이용해서 현재 실행중인 프로세스의 여러 정보를 바탕으로 DDP를 수행할 수 있다. 만들어지는 환경변수는 여기서 확인 가능하다. 1node-Nrank와 달라지는 부분은 기존의 rank 개념이 global_rank로 확장되고 local_rank개념이 생겼다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
class MyDataset(Dataset):
...
class MyModel(nn.Module):
...
def train(epochs):
# torchrun에 의해 생성된 환경변수 사용.
local_rank = os.environ["LOCAL_RANK"]
rank = os.environ["RANK"]
world_size = os.environ["WORLD_SIZE"]
# 환경 변수를 통해서 master 노드의 주소를 작성해야한다.
init_process_group(backend="nccl")
# 동일한 노드 안에 GPU가 여러개 있기 때문에 local_rank에 맞춰서 GPU 할당.
torch.cuda.set_device(local_rank)
my_dataset = MyDataset()
# 모델은 DistributedDataParallel 감싼다.
my_model = DistributedDataParallel(
MyModel().to(device),
device_ids=[local_rank]
)
my_loss = MyLoss()
optimizer = torch.optim.SGD(my_model.parameters(), ...)
# dataset을 각 rank에 분배해야하기 때문에 DistributedSampler를 설정.
my_dataloader = Dataloader(
my_dataset,
sampler = DistributedSampler(my_dataset),
...,
)
for epoch in range(epochs):
# epoch에 따라서 shuffle order가 변경될 수 있도록 설정.
my_dataloder.sampler.set_epoch(epoch)
for data, target in my_dataloder:
data = data.to(device)
target = target.to(device)
optimizer.zero_grad()
output = my_model(data)
loss = my_loss(output, target)
loss.backward()
optimizer.step()
if rank == 0:
# Ring-AllReduce에 의해 동일한 gradient를 가져서,
print("rank0인 master에서만 모델 저장.")
destroy_process_group()
if __name__ == '__main__':
# 동일 노드 안으로 world_size가 GPU개수와 같다.
world_size = torch.cuda.device_count()
# torchrun이 멀티프로세싱까지 동작, 스크립트는 단일 프로세스 세팅.
train(10)
torchrun은 아래와 같이 실행시킬 수 있다. 각 노드에서 해당 명령을 실행시켜주어야 한다.
1
2
3
4
5
6
torchrun --nproc_per_node=${노드당프로세스수} \
--nnodes=${노드수} \
--node_rank=${노드의순서번호}
--master_addr=${마스터노드의IP} \
--master_port=${사용할포트} \
train.py
Fault-tolerant 대처: 학습중 중단에 종료되는 경우 모델의 저장이 필요하다. gradient는 공유되지만 각 프로세스의 학습 관련 모듈들은 독립적이기 때문에 optimizer, lr_scheduler등 파라미터의 저장이 필요한 모듈들은 모든 랭크에서 저장해야한다. (학습 종료 후 최종 모델은 rank0 에서만 저장해도 무관하다.)
라이브러리 설정
나의 학습 환경은 앞서 언급했던것처럼 AWS 클라우드이고 mlflow로 학습 로깅을, skypilot을 통해서 학습 실행을 동작하는 구조이다. skypilot은 ddp를 지원하기에 몇가지 설정만으로 쉽게 적용할 수 있었다.
skypilot
skypilot 설정은 매우 간단하다. skypilot 자체에서 인스턴스를 띄울때 환경변수를 만들어 주기때문에 yaml 파일에 아래처럼 정의만 해주면 된다. 포트는 docs에 8008번으로 고정되어 있어서 그대로 사용하였고 동일한 VPC를 이용하도록 config를 수정해주었다.
1
2
3
4
5
6
7
8
9
10
11
12
num_nodes: 20
...
run: |
num_nodes=`echo "$SKYPILOT_NODE_IPS" | wc -l`
master_addr=`echo "$SKYPILOT_NODE_IPS" | head -n1`
torchrun --nproc_per_node=${노드당프로세스수} \
--nnodes=$num_nodes \
--node_rank=${SKYPILOT_NODE_RANK} \
--master_addr=$master_addr \
--master_port=8008 \
train.py
mlflow
mlflow의 경우는 DDP관련 설정이 없는지 불편했는데 함수를 제정의하고 데코레이터를 붙혀서 rank에 따라서 로깅 여부를 결정하도록 구성하였다. 특히 큰 모델을 다루다 보니 mlflow에서 checkpoint를 불러오다가 timeout이 나는 상황이 발생해서 몇가지 설정도 변경해주었다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class WrapperMlflow:
def __init__(self, rank, is_activated=False):
self.rank = rank
# mlflow 로깅여부 결정.
self.is_activated = is_activated
@staticmethod
def _decorator(f):
@functools.wraps(f)
def _wrapper(self, *args, **kwargs):
if self.is_activated:
return f(self, *args, **kwargs)
else:
return None
return _wrapper
...
@activate_mlflow(None)
def log_artifact(
self,
local_path: str,
artifact_path: Optional[str] = None
):
if self.rank == 0:
return mlflow.log_artifact(
local_path=local_path,
artifact_path=artifact_path,
)
else:
return None
gunicorn 옵션을 변경하여 중간에 저장한 artifacts를 mlflow에서 가져와도 timeout오류가 발생하지 않도록 방지했다.
1
mlflow server --gunicorn-opts "-t 0" ...
mlflow의 경우 서비스를 열어두고 connection을 닫으면 S3의 artifact 연결이 안되는 현상이 있어서 nohup을 이용해서 종료되지 않도록 관리해주고 있다. (감으로는 web과 관련된 특정 프로세스가 종료되는듯 하다.)